Posted inSocial Media Marketing
Best Time to Post on TikTok in 2026: An Analysis of 7.1 Million Posts
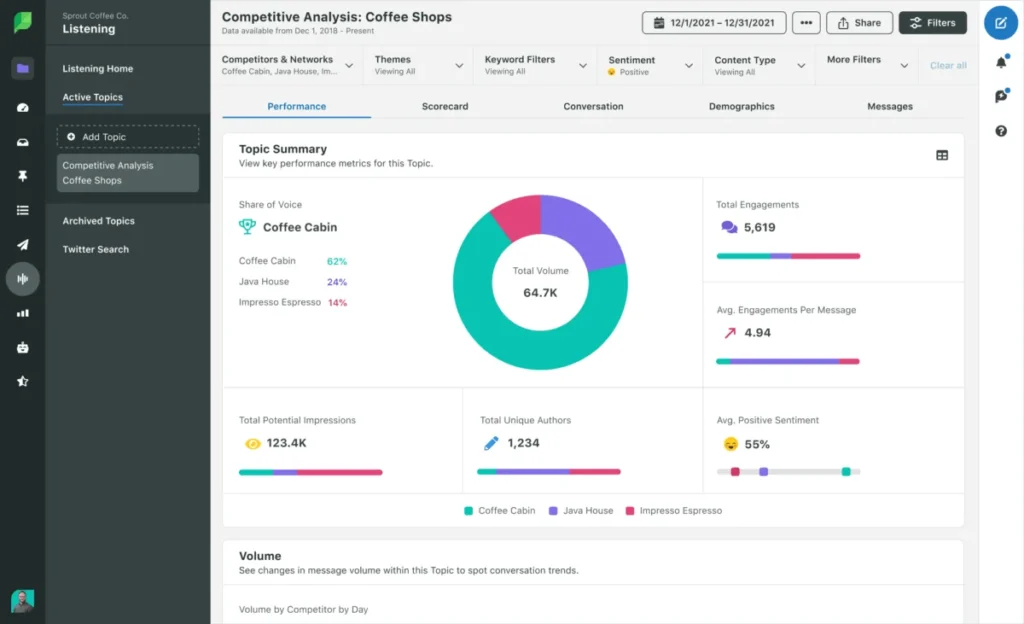
The landscape of social media engagement has undergone a seismic shift as we move through 2026, with TikTok solidifying its position as the primary engine for digital culture and consumer…