Posted inDigital Marketing
Google Ads Editor 2.13 Unveils Major AI Integration, Performance Max Enhancements, and Strategic Campaign Shifts for Global Advertisers
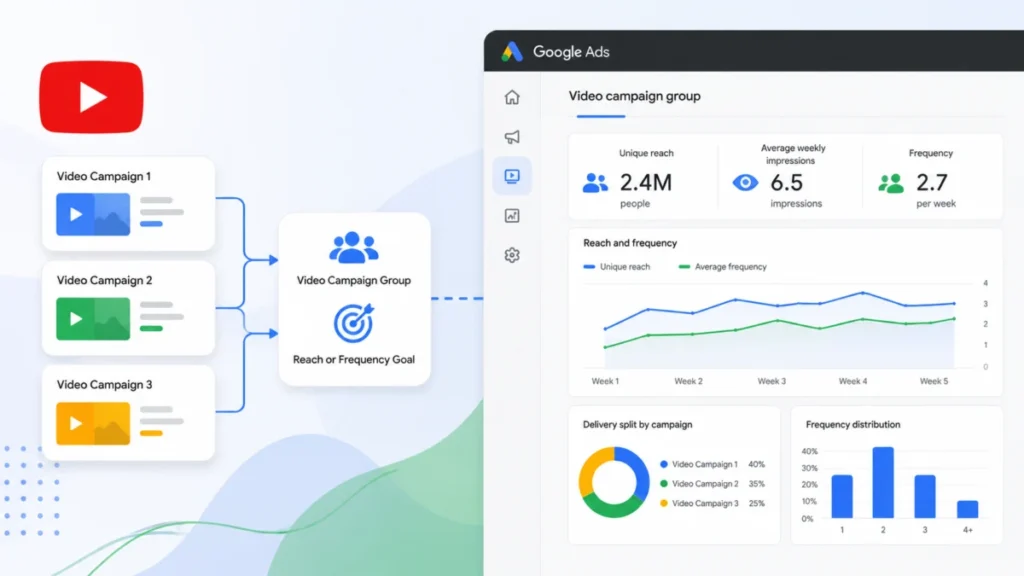
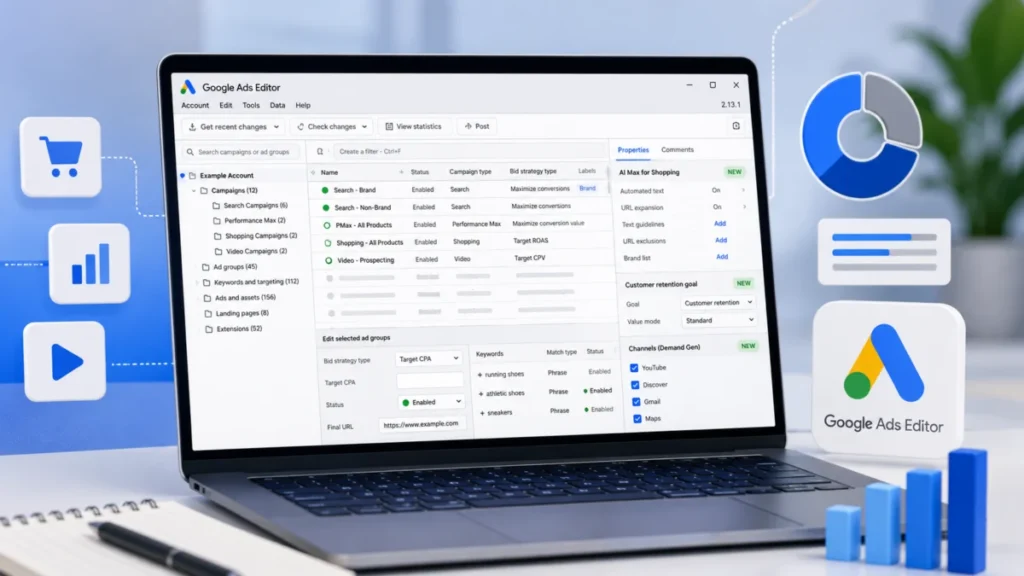
Google has commenced the rollout of Google Ads Editor 2.13, a substantial update poised to redefine offline campaign management for advertisers worldwide. This latest iteration introduces critical support for AI…