Posted inMotion Graphics and Video Production
Advanced Techniques for Achieving Neutral White Balance and Removing Yellow Color Casts in Professional Video Post-Production Workflows
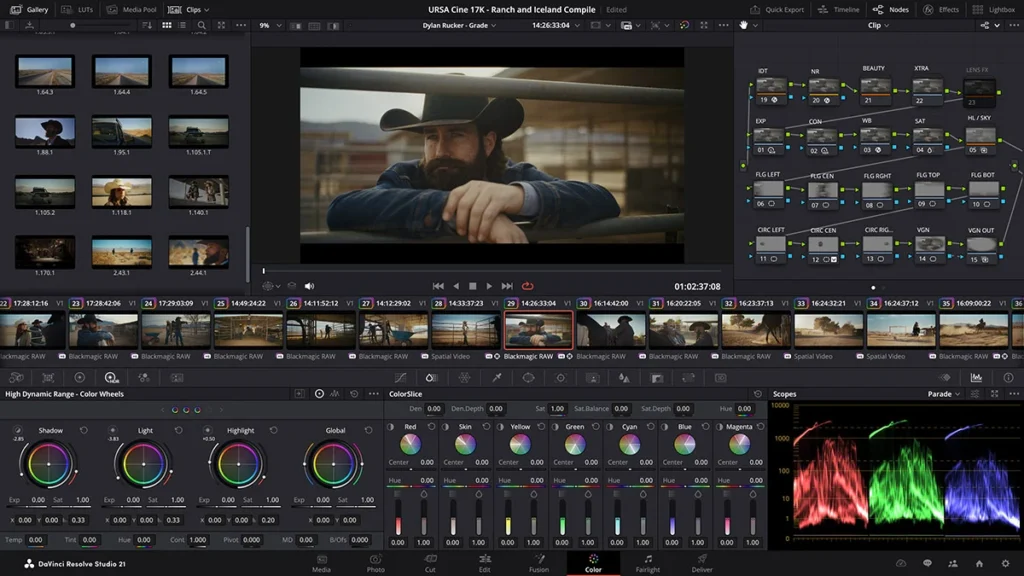
In the high-stakes environment of professional digital cinematography, the integrity of color representation remains a primary metric for production quality. One of the most persistent challenges faced by editors and…