
Recent industry observations underscore the critical need for resilient web applications, particularly in environments with inconsistent internet access. A developer’s experience in late 2025, attempting to demonstrate a project management tool, highlighted how even a seemingly connected Wi-Fi network could render a sophisticated application unusable, displaying blank screens and timeout errors. This incident, emblematic of widespread challenges in traditional client-server architectures, spurred a significant re-evaluation of fundamental web development paradigms, leading many to seriously explore local-first approaches.
The Genesis and Evolution of Local-First Software
The concept of "local-first software" gained prominence with the publication of the seminal "Local-First Software" paper by Ink & Switch in 2019. Initially perceived by many as an academic ideal rather than a practical solution for real-world applications, the paper outlined seven core ideals for software: fast, multi-device, offline, collaboration, longevity, privacy, and user ownership. At the time, the tooling required to achieve these goals was nascent. However, seven years later, advancements in web technologies have transformed these aspirations into tangible engineering requirements. Developers who once dismissed local-first are now actively implementing it, driven by a growing demand for applications that deliver instant responsiveness and robust offline functionality, regardless of network conditions.
This shift is largely enabled by the maturation of technologies such as WebAssembly (WASM) and the Origin Private File System (OPFS). WebAssembly allows developers to run high-performance code, like database engines, directly in the browser, while OPFS provides web applications with a sandboxed, high-performance file system. These innovations have bridged the gap between theoretical concepts and practical, scalable implementations, fundamentally changing how data can be managed on the client side.
Defining Local-First: A Crucial Distinction
A persistent area of confusion in the developer community revolves around the precise definition of local-first. It is frequently conflated with "offline-first" or Progressive Web Apps (PWAs), but these terms describe distinct concepts. Offline-first refers to an application’s ability to function gracefully during network loss, typically by caching server-sourced data; the server remains the ultimate source of truth. PWAs are a delivery mechanism, offering installability, caching, and push notifications, but do not dictate the underlying data architecture.
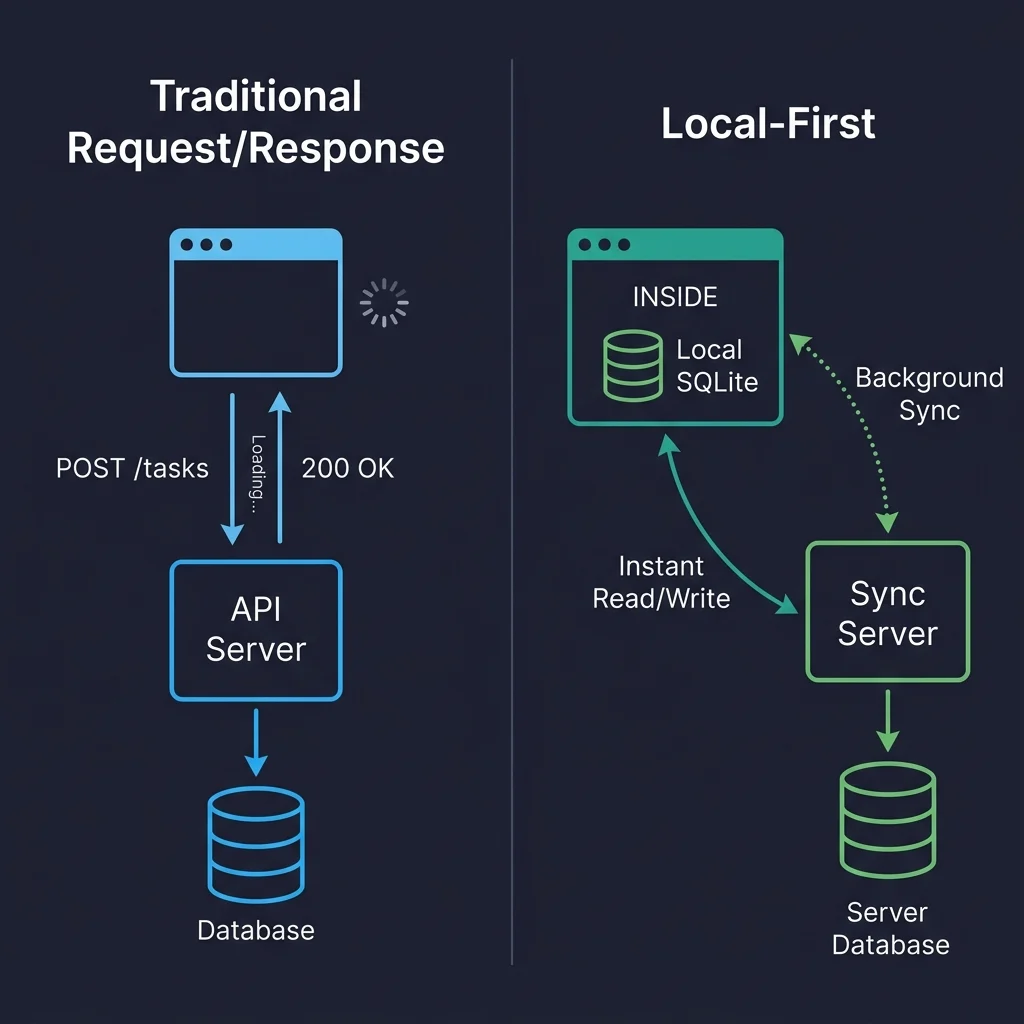
Local-first, in contrast, is fundamentally a data architecture. In this paradigm, the user’s device holds the primary, authoritative copy of their data. The application reads from and writes to a local database, enabling instantaneous rendering and interaction. Synchronization with servers or other devices occurs asynchronously in the background. The server, when present, acts as a specialized peer in a distributed system, handling authentication, backups, and access control, rather than serving as the sole gatekeeper of data. The core tenet, as articulated in the Ink & Switch paper, is that "the client is not a thin view requesting permission to show data. The client is a node in a distributed system with its own database." This distinction profoundly alters the entire application stack and development approach.
Strategic Adoption: When Local-First Is the Right Choice
While the benefits of local-first architecture are compelling, it is not a universal solution. Industry experts caution against shoehorning it into projects where it doesn’t align with core requirements. Local-first is generally a poor fit for applications where data is primarily server-generated, such as analytics dashboards, social media feeds, or search results, where client consumption via API requests is entirely appropriate. Similarly, systems demanding strong transactional consistency, like banking, payment processing, or inventory management, require a single, authoritative database with ACID (Atomicity, Consistency, Isolation, Durability) guarantees, where eventual consistency could lead to critical errors or financial losses. It is also often overkill for simple CRUD (Create, Read, Update, Delete) applications without significant offline or collaboration needs, and impractical for datasets too large to fit on client devices.
However, local-first truly excels in applications involving user-generated data that benefit from instant interaction and resilience against server outages. This includes note-taking applications, document editors, collaborative design tools, project management systems, and field applications operating with unreliable connectivity. It is particularly advantageous where data privacy is a key selling point, or where real-time collaboration is a core feature. A pragmatic approach, often recommended by seasoned developers, is to adopt local-first principles for specific features within larger, otherwise traditional applications, such as offline drafting in a blog editor or real-time collaborative notes within a standard project management tool. This "spectrum of local-first" allows teams to incrementally leverage its benefits without a full architectural overhaul.
The Architectural Shift: Replicas, Not Requests
The mental model for local-first web development closely mirrors that of distributed version control systems like Git. Unlike centralized systems (e.g., SVN) where the server is the single source of truth and operations halt if it’s offline, Git empowers every developer with a full local clone, enabling local commits, branching, and merging, with remote synchronization occurring only when necessary.
In local-first applications, every client device holds a replica (either full or partial) of the relevant data. Writes occur instantly to this local database, with synchronization to servers or other devices happening asynchronously in the background. Conflicts arising from concurrent modifications are resolved through predefined merge strategies. This paradigm eliminates the need for constant network round-trips for basic CRUD operations. For instance, creating a new task involves a direct write to the local SQLite database, resulting in an instantaneous UI update. This obviates the need for complex data fetching libraries like React Query or SWR, or for managing server-derived state with tools like Redux, as the local database inherently serves as the application’s state.
This fundamental shift is visually represented by contrasting traditional request/response architectures, where every user interaction involves a network round-trip and associated waiting times, with local-first architectures, where reads and writes directly access the local database. The sync server remains crucial but operates non-blockingly, ensuring that user experience remains fluid and responsive, irrespective of network latency.
Client-Side Data Persistence: The Foundational Layer
Effective local-first architecture necessitates robust client-side data storage beyond the limitations of localStorage (synchronous, small capacity, string-only). While IndexedDB, a browser-native asynchronous object store, offers broad compatibility and larger storage capacity, its API is notoriously cumbersome.

The significant breakthrough in 2026 for client-side persistence is the widespread adoption of SQLite running in the browser via WebAssembly (WASM), persisted to the Origin Private File System (OPFS). This combination delivers a full-fledged relational database within the browser environment, supporting complex SQL queries, transactions, and indexing. OPFS, a newer API, provides web applications with a sandboxed, high-performance file system that allows for synchronous access within Web Workers, a crucial capability for SQLite. Prior to OPFS, running SQLite in memory with manual IndexedDB persistence was possible but often slow and fragile.
Libraries like wa-sqlite are instrumental in this approach. However, developers have encountered subtle browser-specific quirks; for example, Safari’s OPFS implementation has historically presented challenges, such as silent failures of createSyncAccessHandle() in certain iframe contexts. While Safari versions 19-26 are reported to address these issues, a fallback to IndexedDB-backed persistence remains a prudent strategy for ensuring cross-browser compatibility.
Other emerging options include PGlite, which brings full PostgreSQL compatibility to the client via WASM, though it currently entails a larger bundle size and higher memory footprint. cr-sqlite, which integrates CRDT column support directly into SQLite, offers an intriguing approach to conflict resolution but is still considered early-stage for many production environments due to the complexity of debugging CRDT state within SQLite.
The Synchronization Imperative: Reconciling Distributed Data
While local data storage is a well-understood problem, reliably syncing data across multiple devices and users remains the most significant challenge in local-first development. When multiple replicas can independently read and write data, a robust mechanism for change reconciliation is essential.
Conflict-Free Replicated Data Types (CRDTs): These are data structures mathematically designed to ensure that concurrent edits can always be merged without conflicts. Yjs is the leading JavaScript implementation, particularly effective for real-time collaborative text editing, where character-level merges produce sensible results. Automerge, another prominent CRDT library, offers a Rust-backed, document-oriented model. Newer Rust-based libraries like Loro promise enhanced performance. While CRDTs excel in certain domains, their merge semantics for structured data (e.g., reordering lists) can sometimes yield unexpected or practically confusing results, necessitating post-merge de-duplication or other application-level adjustments.
Database Replication: For many applications not requiring the granular real-time text editing capabilities of CRDTs, database replication offers a more straightforward approach. This involves replicating rows between a server-side database (e.g., PostgreSQL) and a client-side database (e.g., SQLite) managed by a specialized sync engine. PowerSync, for instance, provides one-way replication from PostgreSQL to client SQLite with a defined write-back path for mutations. ElectricSQL aims for more ambitious active-active synchronization between PostgreSQL and SQLite, using "shapes" to define data replication. While ElectricSQL offers an excellent developer experience, its maturity for production use is still under active evaluation by the industry. Triplit presents a full-stack database solution with integrated sync, abstracting away the distinction between client and server databases.
Event Sourcing: This approach involves syncing a log of mutations rather than the current state, as seen in systems like LiveStore. While intellectually appealing and useful for audit trails, reconstructing application state from an event log can introduce significant complexity that many typical applications may not require. Debates within the developer community persist regarding the optimal use cases for event sourcing in application development.
Navigating Conflicts: Strategies for Data Coherence
Conflict resolution, often perceived as a daunting problem, is a manageable challenge that demands careful consideration of the specific data model. Conflicts arise when two replicas modify the same data concurrently without immediate awareness of each other’s changes.
A common and effective strategy for most data types is field-level last-write-wins (LWW), rather than record-level. If User A modifies a task title and User B modifies its due date, both changes are preserved because they affect different fields. A true conflict only occurs when the same field is modified, in which case the later timestamp (with client ID as a deterministic tiebreaker) dictates the winning value. This approach typically resolves approximately 95% of conflicts without requiring user intervention, as silently overwriting a task title, for example, is often acceptable.
A more subtle challenge lies in semantic conflicts. These occur when data merges cleanly at a structural level, but the combined result is logically inconsistent or nonsensical (e.g., two users booking the same meeting slot with different meetings). Such conflicts necessitate application-level validation, which must occur on the server during the synchronization process. The recommended approach involves the server accepting the structurally merged write but flagging any domain invariant violations, rather than outright rejecting them. Rejecting a write can lead to state divergence, where the client’s local database contains records the server refuses to acknowledge, creating "ghost records" that are challenging to resolve.
Instead, the server accepts the write, stores the violation (e.g., a SyncViolation record detailing a scheduling conflict), and syncs this violation back to the client. The client then presents a non-blocking notification to the user, prompting them to resolve the conflict (e.g., reschedule one of the conflicting meetings). This approach ensures that client and server states remain consistent, albeit with a temporary window of semantic inconsistency. While not perfectly elegant, it provides a robust mechanism for handling complex domain-specific rules in a distributed environment. For high-stakes content like legal or medical documents, where silent data loss is unacceptable, user-facing conflict resolution (akin to Git merges) may be required.
Key Tools and Ecosystem in Mid-2026
The local-first ecosystem is evolving rapidly. As of mid-2026, several tools stand out:
- Yjs: Remains the most mature and widely adopted CRDT library, ideal for real-time collaborative text editing, with extensive integrations with popular editors.
- Automerge: A robust, Rust-backed CRDT library, well-suited for document-oriented data models.
- PowerSync: Highly recommended for teams with existing PostgreSQL backends seeking to integrate offline support. Its one-way replication model and clear write-back path are well-documented and production-ready.
- ElectricSQL: An ambitious project aiming for true active-active replication between PostgreSQL and SQLite. While offering an excellent developer experience in prototypes, its production maturity is still under scrutiny.
- Triplit: A full-stack database with integrated sync and a promising TypeScript API, suitable for rapid prototyping and potentially smaller-scale production applications.
- Zero (Rocicorp): An interesting query-based synchronization approach, succeeding Replicache. It is still in an early development phase, but warrants close observation.
- TinyBase: A lightweight reactive store, excellent for smaller applications and personal projects.
- PGlite: A groundbreaking technology bringing full PostgreSQL to WASM, hinting at a future where client/server data layer distinctions dissolve, though bundle size and memory footprint remain considerations.
A critical lesson learned from the rapid evolution of this space, including the sunsetting of tools like Replicache, is the importance of architectural abstraction. Designing sync layers to be interchangeable mitigates the risk of vendor lock-in and allows for adaptability in a fast-moving ecosystem.
Building a Real Application: Architecture, Authentication, and Migrations

A typical local-first application stack in 2026 might involve React for the frontend, PowerSync for data synchronization, SQLite via wa-sqlite on the client (persisted to OPFS with IndexedDB as a Safari fallback), and Supabase (leveraging PostgreSQL, authentication, and row-level security) for the backend.
The component code in such an architecture becomes notably simpler. Local reads and writes eliminate the need for complex loading states, error handling for write operations, optimistic updates with rollback logic, or extensive cache invalidation.
Authentication: Operates similarly to traditional web applications, utilizing JWT tokens or OAuth flows. The token authenticates the sync connection rather than every individual request. Offline access is seamless as data is already local, having been synced during prior authenticated sessions.
Authorization: A crucial aspect that cannot rely on client-side enforcement, as local data is accessible via developer tools. Authorization is rigorously enforced at the sync layer. Tools like PowerSync employ "sync rules," while ElectricSQL uses "shapes," to define precisely which rows of data a user is authorized to access. Similarly, client-initiated writes are validated against server-side authorization rules before being applied to the backend database.
End-to-End Encryption (E2EE): Naturally complements local-first architecture. Since data resides primarily on the client, it can be encrypted before synchronization. The server then acts as a relay for encrypted blobs it cannot decrypt, offering enhanced data privacy.
Schema Migrations: A unique challenge in local-first development arises from the distributed nature of client databases. Unlike a single server-side database, individual client devices may be running varying schema versions depending on when the app was last opened. An additive migration strategy, involving version tracking within the local database and applying migrations sequentially at app startup, is essential. Migrations should prioritize adding new columns with default values or new tables. Renaming or dropping columns should be approached with extreme caution, as older client versions still syncing data can lead to silent sync failures and state inconsistencies. Detailed logging of migration events is critical for debugging.
Performance: Real Gains and Emerging Bottlenecks
Local-first applications offer genuine performance advantages:
- Instant Reads: Querying a local SQLite database for hundreds or thousands of records typically takes milliseconds, even on mid-range mobile devices, eliminating network latency and spinners.
- Instant Writes: Local database writes are instantaneous, providing immediate UI feedback and a perception of fluid interaction, with background synchronization.
However, challenges remain:
- Initial Sync Cost: Bootstrapping the local replica on first load or a new device involves downloading potentially megabytes of data. Strategies like partial synchronization (syncing only active projects) and user-facing "Setting up your workspace" screens mitigate this initial delay.
- Bundle Size: SQLite compiled to WASM adds approximately 400KB (gzipped) to the JavaScript bundle, which can impact Time to Interactive (TTI) on mobile devices. Lazy loading the database module helps defer this cost.
- Memory Footprint: SQLite WASM operates in memory, and large datasets can lead to tab crashes on mobile browsers with aggressive memory limits. Partial sync and aggressive data pruning are common mitigation strategies. The foundational text "Designing Data-Intensive Applications" by Martin Kleppmann is widely recommended for understanding distributed data challenges.
Testing Local-First Applications
Testing local-first applications presents increased complexity compared to traditional architectures. Effective strategies include:
- Unit Tests: For pure functions, especially merge logic in conflict resolution.
- Integration Tests: Spinning up multiple in-memory client instances to verify data convergence after concurrent edits.
- End-to-End (E2E) Tests: Using tools like Playwright with
context.setOffline(true)to simulate offline/online transitions. - Property-Based Testing: Particularly valuable for CRDT logic, generating random operation sequences and applying them in varying orders to assert convergence.
Reproducing timing-specific conflict resolution bugs remains a significant challenge. Enhanced logging of sync events—detailing sent and received data, detected conflicts, and resolution strategies—is crucial for post-hoc debugging in production environments.
Future Trajectories and Industry Concerns
The future of local-first development is promising. Technologies like PGlite hint at a future where the client/server data layer distinction may dissolve, allowing developers to write SQL that executes universally, with sync becoming a runtime concern. The convergence of local-first with artificial intelligence (AI) also holds significant promise, enabling privacy-preserving AI models that run locally, process on-device data, and interact with cloud AI only with explicit user consent. This "your data never leaves your device" ethos could become a powerful product differentiator.
However, significant concerns persist. Fragmentation is a primary worry; the absence of standardized sync protocols means each sync engine operates with its own proprietary mechanisms, making migration between platforms non-trivial and increasing the risk of vendor lock-in. Industry observers note that despite the web’s extensive standardization efforts across various domains, a standard for data synchronization remains elusive.
Another concern is the complexity budget. Local-first architecture introduces a tangible increase in architectural complexity, encompassing sync engines, intricate conflict resolution, client-side schema migrations, partial replication, and authorization at the sync boundary. For experienced development teams building applications that genuinely benefit from these capabilities, the complexity yields substantial returns in performance and reliability. However, for simpler applications or less experienced teams, this added complexity can become a significant impediment, often leading to over-engineering.
As one developer aptly observed at a recent local-first meetup, "The best architecture is the one your team can debug at 2 AM." This adage underscores the importance of thoroughly understanding the failure modes and operational complexities before committing to a local-first approach. Developers are encouraged to begin with a prototype or integrate local-first principles into a single feature of an existing application to gain practical experience and assess its suitability. This incremental adoption allows teams to experience the transformative benefits of instant local reads and offline writes, often leading to the realization that "this is how it should have always worked."





{kind=link}