
The landscape of web application development is undergoing a significant transformation, with a growing emphasis on "local-first" architecture designed to deliver unparalleled speed, reliability, and user control. This paradigm shift, moving away from purely server-dependent models, is increasingly seen as the answer to the persistent challenges of network latency, intermittent connectivity, and user demands for instant responsiveness. Industry experts, including a developer who transitioned from initial skepticism to becoming a vocal advocate, are now offering a grounded, experience-driven perspective on what it truly means to build these advanced applications in 2026.
The Genesis of a Paradigm Shift: Addressing Connectivity Challenges
The impetus for local-first development often stems from critical failures in traditional server-centric applications. A notable incident involved a project management tool, developed over four months, failing spectacularly during a demo due to unreliable hotel Wi-Fi. The application, built with a modern stack including React, Node, Postgres, Redis, and GraphQL, rendered a blank screen and timeout errors without a stable connection. Even with a shaky cellular tether, every interaction—from creating a task to moving it between columns—was plagued by two-second delays and loading spinners. This real-world scenario, where an application failed to display basic user data without a round-trip to a server thousands of miles away, underscores a common developer frustration and a fundamental flaw in purely cloud-dependent systems. User expectations for instant feedback and seamless operation have risen dramatically; studies indicate that users abandon applications that take longer than two seconds to load, making robust offline capabilities not just a feature, but a necessity for user retention in an increasingly mobile and globally connected world.
Defining Local-First: Beyond Offline and PWAs
A critical distinction often lost in industry discussions is that local-first is not merely "offline-first" or synonymous with Progressive Web Apps (PWAs). While offline-first focuses on gracefully handling network loss, with the server remaining the ultimate source of truth, and PWAs are a delivery mechanism for installable, cached, and notification-enabled web experiences, local-first represents a fundamental shift in data architecture. In a local-first model, the user’s device holds the primary, authoritative copy of their data. The application reads and writes directly to a local database, enabling instant rendering and interactions. Synchronization with servers or other devices occurs asynchronously in the background. The server, when present, acts as a sophisticated sync peer, handling authentication, backups, and access control, rather than serving as the sole gatekeeper of data.
This architectural philosophy was first articulated in the seminal 2019 "Local-First Software" paper by Ink & Switch, which outlined seven core ideals: fast, multi-device, offline, collaboration, longevity, privacy, and user ownership. Initially dismissed by many, including the aforementioned developer, as "cool research, not practical for real apps," these ideals are now becoming engineering requirements as tooling matures. The core tenet is that "the client is not a thin view requesting permission to show data. The client is a node in a distributed system with its own database." This seemingly subtle shift dictates the entire application stack, empowering users with greater data control and ensuring application resilience.
Strategic Application: When Local-First Excels and When It Doesn’t
While local-first architecture offers compelling advantages, it is not a universal solution. Expert consensus advises caution against shoehorning it into projects where it provides little benefit or introduces unnecessary complexity. For instance, applications where data is predominantly server-generated—such as analytics dashboards, social media feeds, or search results—are ill-suited for a local-first approach. In these scenarios, the client merely consumes data produced by the server, making traditional API requests perfectly adequate.
Furthermore, systems requiring strong transactional consistency, like banking platforms, payment processing, or inventory management, are fundamentally incompatible with the eventual consistency inherent in most local-first models. If two users attempt to purchase the last item in stock, an authoritative, ACID-compliant server database is indispensable to prevent critical errors. Similarly, simple CRUD (Create, Read, Update, Delete) applications without explicit offline or real-time collaboration requirements may find local-first an instance of over-engineering. Physically impractical for massive datasets that cannot fit on client devices, it also presents challenges for data management at scale.
Conversely, local-first architecture shines in domains centered around user-generated data that benefits from instant interaction and resilience. This includes note-taking applications, document editors, collaborative design tools, project management suites, and field-based apps operating with unreliable connectivity. It is particularly powerful for applications where data privacy and real-time collaboration are key selling points. The flexibility of local-first also allows for a phased adoption, where specific features within an otherwise traditional application—such as offline drafts in a blog editor or real-time collaborative notes—can leverage local-first patterns, rather than requiring a complete architectural overhaul. This "spectrum of local-first" approach allows teams to incrementally adopt the architecture where it provides the most value, mitigating initial risks.
The Core Principle: Replicas Over Requests
The fundamental shift in local-first development can be understood through a Git analogy. Unlike centralized version control systems (like SVN), where commits depend on server availability, Git provides every developer with a full local clone, enabling local commits, branching, and merging, with remote repositories serving as important but not singular sources of truth. Local-first web development applies this decentralized model to application data. Each client device holds a replica (which can be full or partial) of the relevant data. Writes are performed locally and instantly reflected in the UI, as the application reads directly from this local database. Synchronization then occurs in the background, pushing and pulling changes with a server or other devices. Conflicts, when they arise, are resolved through predefined merge strategies.

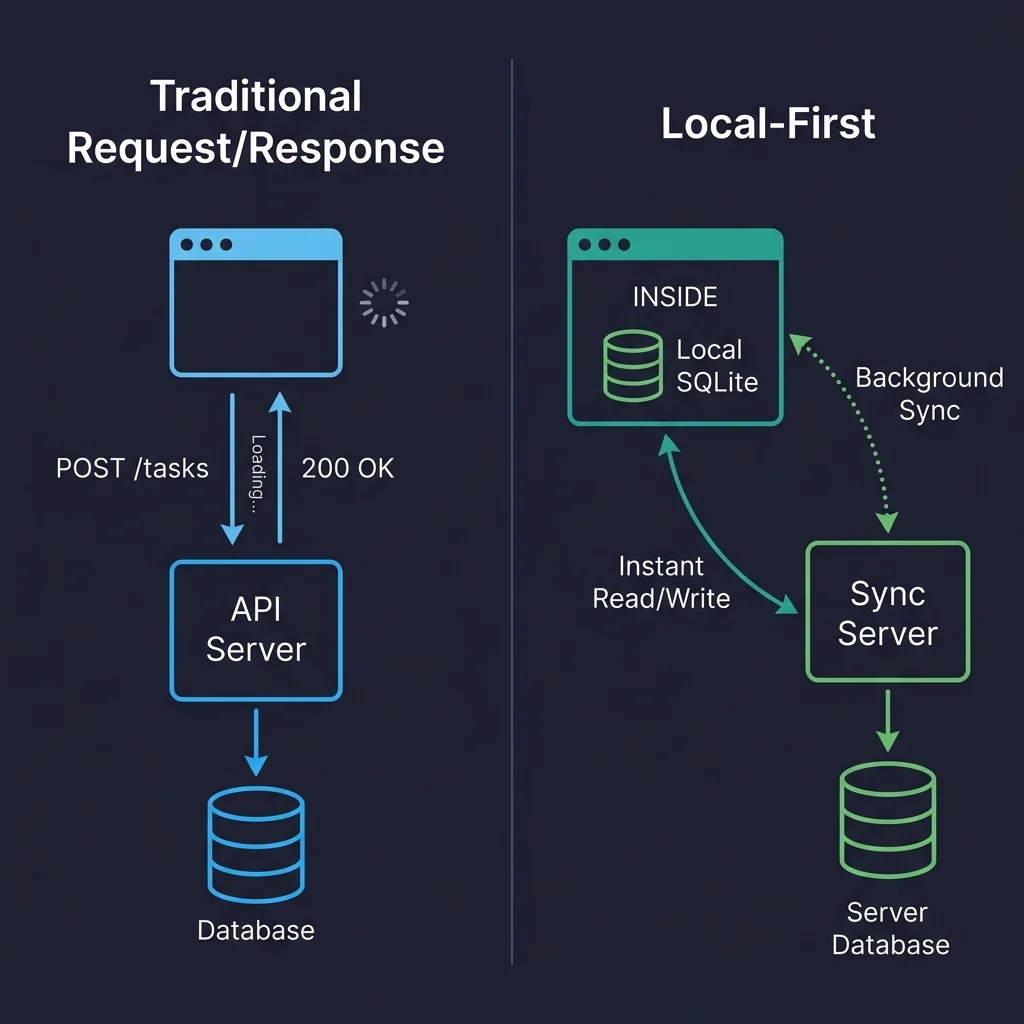
This architectural choice eliminates the need for common server-side data fetching patterns seen in traditional applications. Libraries like React Query or SWR become largely redundant, as data is no longer "fetched" from a remote server but accessed directly from the local database. State management libraries like Redux or Zustand are simplified, as the local database is the application’s primary state. Routing no longer triggers API calls, and authentication mechanisms adapt, with tokens authenticating the sync connection rather than every individual read operation. The visual comparison between traditional request/response architectures and local-first models starkly illustrates this: every user interaction in the former involves a round-trip, leading to perceived delays, whereas in the latter, reads and writes are instantaneous against the local database, with background synchronization ensuring data consistency.
Client-Side Data Storage: The Rise of SQLite via WebAssembly
The practicality of local-first hinges on robust client-side data storage, a domain that has seen significant evolution. Obsolete solutions like localStorage, with its synchronous blocking behavior, string-only storage, and meager 5-10 MB limits, are clearly inadequate for data-intensive applications. IndexedDB, while asynchronous, capable of handling hundreds of megabytes, and present in every modern browser, is notorious for its cumbersome API and developer experience.
The game-changer in 2026 is SQLite running directly in the browser via WebAssembly (WASM). This is far from a mere "party trick"; it represents a real relational database environment within the browser, offering full SQL queries, transactions, and indexing capabilities. The critical enabler for this is the Origin Private File System (OPFS), a newer browser API that provides web applications with a sandboxed, high-performance file system, crucial for SQLite’s synchronous file access needs within Web Workers. Before OPFS, running SQLite involved complex and often fragile manual persistence to IndexedDB. Libraries like wa-sqlite are now making this practical, though developers note subtle behavioral differences between browser implementations (e.g., Safari’s OPFS). The rapid adoption of WebAssembly across browsers, coupled with ongoing improvements in file system APIs, signifies a clear trajectory towards more powerful and native-like data storage capabilities for web applications. Emerging alternatives like PGlite (Postgres compiled to WASM) and cr-sqlite (SQLite with CRDT column support) further indicate the innovative pace of this space, pushing the boundaries of what’s possible directly on the client.
The Crux of Complexity: Data Synchronization and Conflict Resolution
While local data storage is now largely a solved problem, reliably syncing data across multiple devices and users, particularly in the face of concurrent modifications, remains the most challenging aspect of local-first architecture. When multiple replicas can independently read and write, a robust mechanism for reconciling changes is essential.
Broadly, four main approaches have emerged:
- CRDTs (Conflict-Free Replicated Data Types): These are data structures mathematically designed to ensure that concurrent edits can always be merged without conflicts. Yjs is a leading JavaScript implementation, particularly excellent for real-time collaborative text editing. Automerge and the newer Loro are other prominent CRDT libraries, offering document-oriented models with varying performance characteristics. While highly effective for certain data types, CRDT merging of structured data (e.g., list reordering) can sometimes produce semantically surprising results, requiring additional application-level post-processing.
- Database Replication: This approach involves replicating rows between a server database (e.g., Postgres) and a client database (e.g., SQLite), with a specialized sync engine managing the data flow. Solutions like PowerSync offer one-way replication from server to client with a write-back path for mutations, while ElectricSQL aims for more ambitious active-active synchronization. This method often feels more natural for applications dealing with traditional relational data models.
- Event Sourcing: This involves syncing a log of mutations rather than the current state. While intellectually appealing for audit trails and specific domains, many developers find that reconstructing state from an event log adds significant complexity that most general-purpose applications do not require.
- Query-based Sync: Newer approaches like Rocicorp’s Zero are exploring query-based synchronization, moving away from simple row replication to a more declarative model.
Conflict resolution itself is a critical area. Naive strategies, such as always taking the remote version, lead to silent data loss. A more effective general strategy is field-level last-write-wins (LWW). This means if User A changes a task title and User B changes its due date while offline, both changes are preserved because they affect different fields. A conflict only arises if both modify the same field, in which case the later timestamp (with a client ID as a deterministic tiebreaker) prevails. This handles approximately 95% of conflicts without user intervention.
However, a more insidious challenge is semantic conflicts, where data merges structurally cleanly but results in nonsensical application state (e.g., two users booking the same meeting slot with different meetings). Resolving these requires application-level validation on the server during the write-back phase. The recommended approach is to flag violations rather than silently rejecting them. The server accepts the write, stores the violation, and syncs it back to the client, which then presents a non-blocking notification to the user, allowing them to manually resolve the issue (e.g., reschedule one of the conflicting meetings). This avoids divergent client/server states, which are notoriously difficult to recover from. The complexity of managing a parallel set of business rules for validation on the server, and the potential for a temporary window where conflicting states exist, highlights the trade-offs inherent in distributed systems.
Navigating the Tooling Landscape of 2026
The local-first ecosystem is dynamic, with new tools and approaches emerging rapidly. As of mid-2026, several key players stand out:
- Yjs: Remains the most mature and widely adopted CRDT library, production-ready with a large community and extensive integrations with collaborative editors (TipTap, BlockNote, Lexical). It is the go-to for real-time collaborative text editing.
- Automerge: A robust, Rust-backed CRDT library, favored in document-oriented applications. Its core engineering is highly regarded, though it has fewer integrations than Yjs.
- PowerSync: Highly recommended for teams with existing Postgres backends seeking to add offline capabilities. It offers stable, one-way replication from Postgres to client SQLite with a well-defined write-back path, making its mental model easy to reason about. Initial sync performance is generally acceptable for typical application datasets.
- ElectricSQL: Aims for more ambitious true active-active replication between Postgres and SQLite, using "shapes" to define client-specific data subsets. While promising and offering an excellent developer experience in prototypes, it is still maturing, with some rough edges noted around shape management and reconnection behavior in early 2026.
- Triplit: A full-stack database with built-in sync and a pleasant TypeScript API. While impressive in prototypes, its production readiness under heavy load is yet to be fully established.
- Zero (from Rocicorp): An evolution of the earlier Replicache, Zero employs a query-based sync approach. It is an interesting project to watch, but generally considered early-stage for production commitments.
- PGlite: Postgres compiled to WebAssembly, enabling the same SQL dialect on both client and server. This technology hints at a future where the client/server data layer distinction blurs, though its bundle size and memory footprint remain considerations for widespread mobile adoption.
Industry observers caution against betting an entire architecture on a single, early-stage tool from a small company without a robust fallback plan, given the rapid evolution and potential for tool deprecation (as seen with Replicache). Abstracting the sync layer is a recommended strategy to mitigate this risk.
Architecting a Production-Ready Local-First Application

A practical local-first application stack in 2026 might typically involve React for the front end, PowerSync for robust data synchronization, SQLite via wa-sqlite on the client (persisted to OPFS with IndexedDB as a Safari fallback), and Supabase (offering Postgres, authentication, and row-level security) for the server-side backend. This setup significantly simplifies component code, eliminating the need for complex loading states, error handling, optimistic updates, and cache invalidation, as all reads and writes are local and instantaneous.
Authentication in a local-first world operates similarly to traditional apps, using JWT tokens or OAuth flows for session management. However, the token authenticates the sync connection rather than every individual request. Offline access is inherently supported because data is already present locally, authenticated during the initial sync. Authorization is enforced at the sync layer, with server-side "sync rules" or "shapes" defining which rows a client is authorized to receive. Any unauthorized write attempts from the client are rejected by the server during synchronization. End-to-end encryption (E2EE) naturally complements local-first, allowing data to be encrypted on the client before sync, with the server acting as a relay for encrypted blobs it cannot read, enhancing privacy.
Schema migrations pose a unique challenge. Unlike server-side migrations, which target a single, controlled database, client-side migrations must account for thousands of individual user databases, each potentially running an arbitrary older schema version. The solution involves an additive migration strategy: new columns with defaults, and new tables. Renaming or dropping columns is generally avoided unless absolutely necessary, as older client versions might still be writing to them, causing silent sync failures. A simple migration runner at app startup checks the local schema version and applies pending additive migrations, typically wrapped in database transactions for safety.
Performance Metrics and Operational Challenges
The performance benefits of local-first are immediate and tangible. Reads from a local SQLite database are virtually instantaneous, often under two milliseconds on modern hardware, eliminating network latency and spinners. Writes are similarly instant, as they are applied locally, with UI updates occurring reactively and synchronization happening in the background.
However, this comes with its own set of performance and operational considerations. The primary cost is the initial sync, where the local replica is bootstrapped on first load or a new device, potentially downloading megabytes of data. While incremental updates are tiny, initial sync for a moderately sized workspace (e.g., 5,000 tasks, 200 projects, 50 users) can take several seconds on slower connections. This is mitigated through partial syncs (only syncing active data) and user-facing "Setting up your workspace" screens.
Bundle size is another concern; SQLite compiled to WASM adds roughly 400KB (gzipped) to the JavaScript bundle, necessitating lazy-loading to prevent blocking initial renders. Memory management is also critical, particularly on mobile browsers with aggressive limits, where large local databases can lead to tab crashes. Strategies include keeping synced datasets small and aggressive pruning of old data.
Testing local-first applications is inherently more complex than traditional ones. While unit tests for merge logic are straightforward, integration tests require spinning up multiple client instances in memory to verify data convergence after concurrent edits. End-to-end tests leveraging browser automation tools (e.g., Playwright’s context.setOffline(true)) are crucial for simulating offline/online transitions. Reproducing and debugging intermittent conflict resolution bugs, often dependent on precise timing and sequence of events, remains a significant challenge, necessitating detailed sync event logging and observability. Property-based testing is increasingly valuable for CRDT logic, generating random operation sequences to assert convergence.
Future Outlook and Lingering Concerns
The future of local-first web development is promising. Technologies like PGlite, offering full Postgres capabilities in the browser, hint at a future where the distinction between client and server data layers dissolves, allowing developers to write SQL that runs universally. The convergence of local-first principles with artificial intelligence is also an exciting prospect. Running AI models locally, keeping data on-device, and using cloud AI only with explicit consent, combined with E2EE, could make "your data never leaves your device" a powerful product differentiator, especially as AI integrates more deeply into software experiences.
Despite this optimism, significant challenges remain. Fragmentation is a major concern; the absence of a standardized sync protocol means each sync engine uses its own proprietary approach. This lack of interoperability creates vendor lock-in and complicates migration between platforms. While the web platform boasts standards for nearly everything, a universal standard for sync is not yet on the horizon.
Moreover, the complexity budget is a critical consideration. Local-first architecture introduces real architectural overhead: sync engines, sophisticated conflict resolution, client-side migrations, partial replication, and nuanced authentication at the sync boundary. For experienced development teams building applications that genuinely benefit from these features, this complexity is a worthwhile investment. However, for simpler applications or less experienced teams, it can become a significant trap, leading to increased development time, maintenance overhead, and debugging challenges. As one developer aptly put it, "The best architecture is the one your team can debug at 2 AM."
The strategic importance of local-first principles for modern web development cannot be overstated. For those embarking on this journey, the recommendation is to start small: identify a single feature in an existing application that would benefit from instant local reads and offline writes, implement a local SQLite database, and wire up reactive queries. This incremental approach allows teams to experience the transformative power of local-first firsthand, understanding its nuances before committing to broader adoption, and ultimately realizing a vision of web applications that are faster, more reliable, and more empowering for users.




{kind=link}