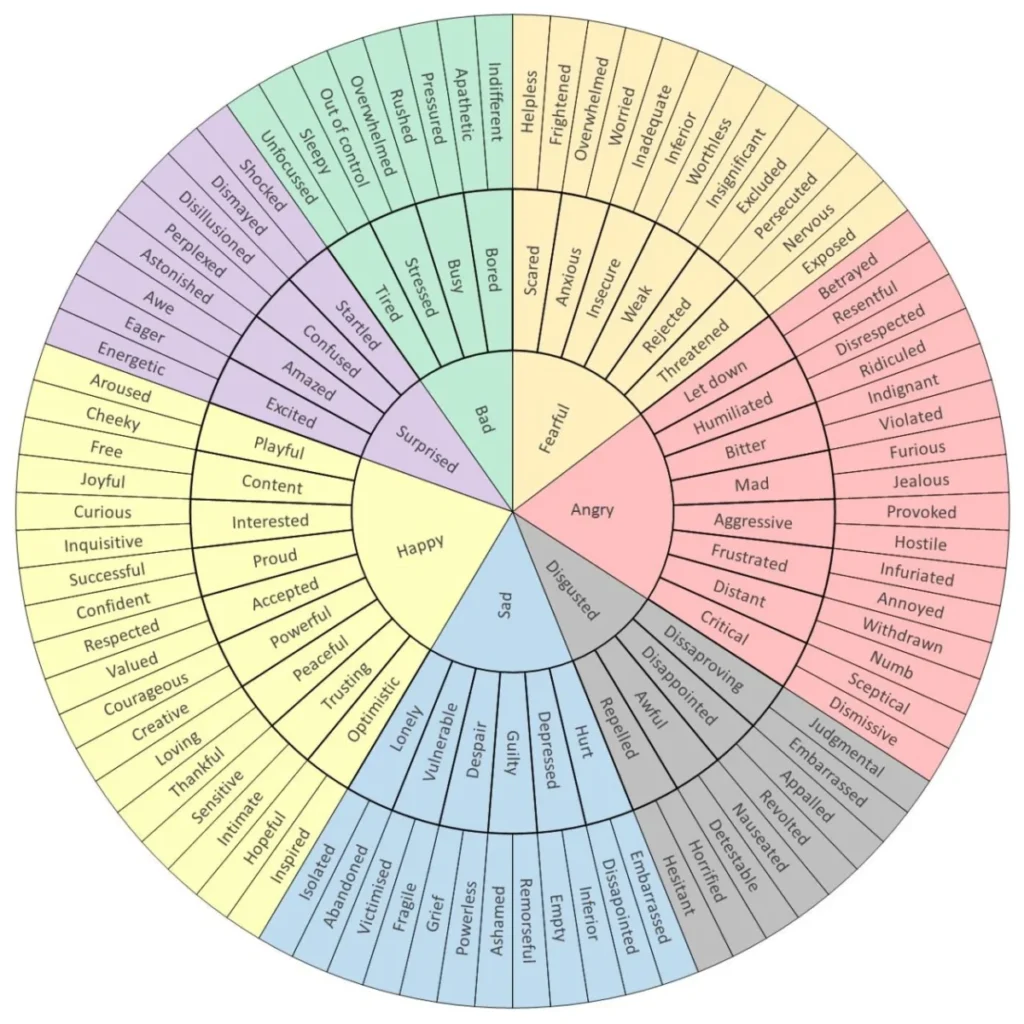
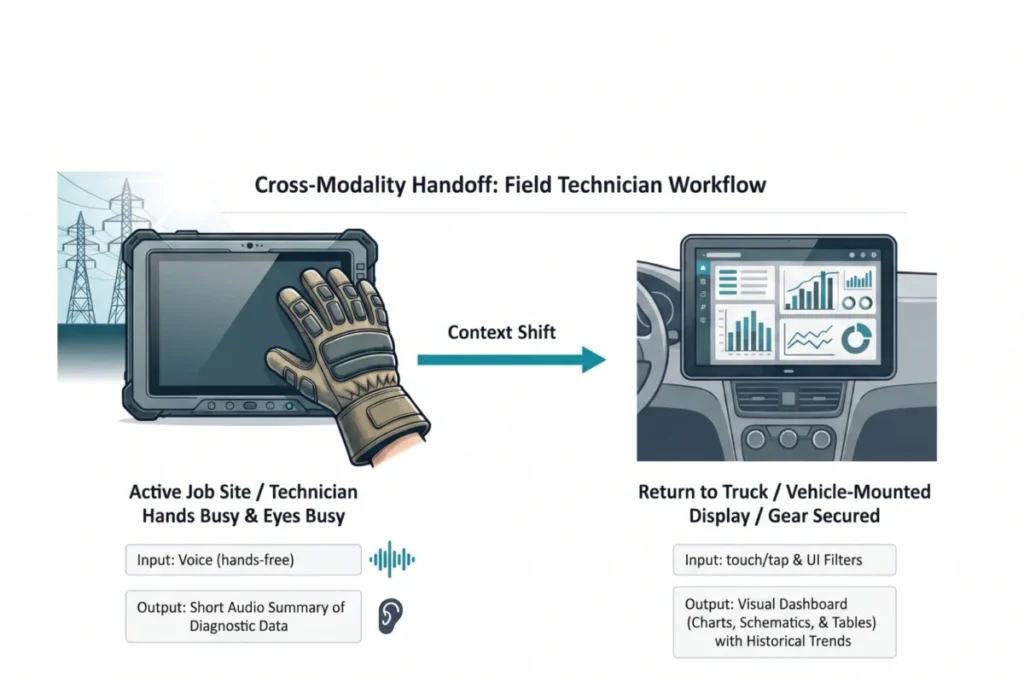
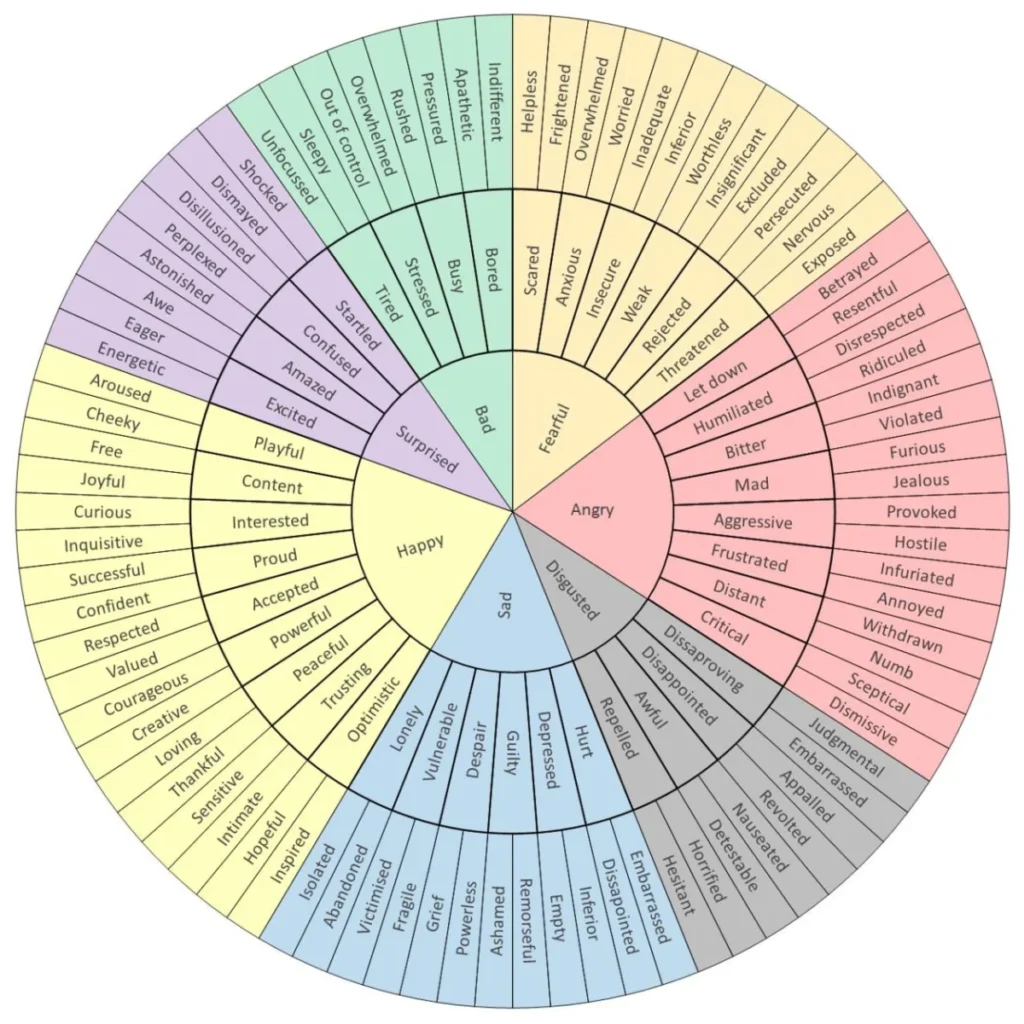
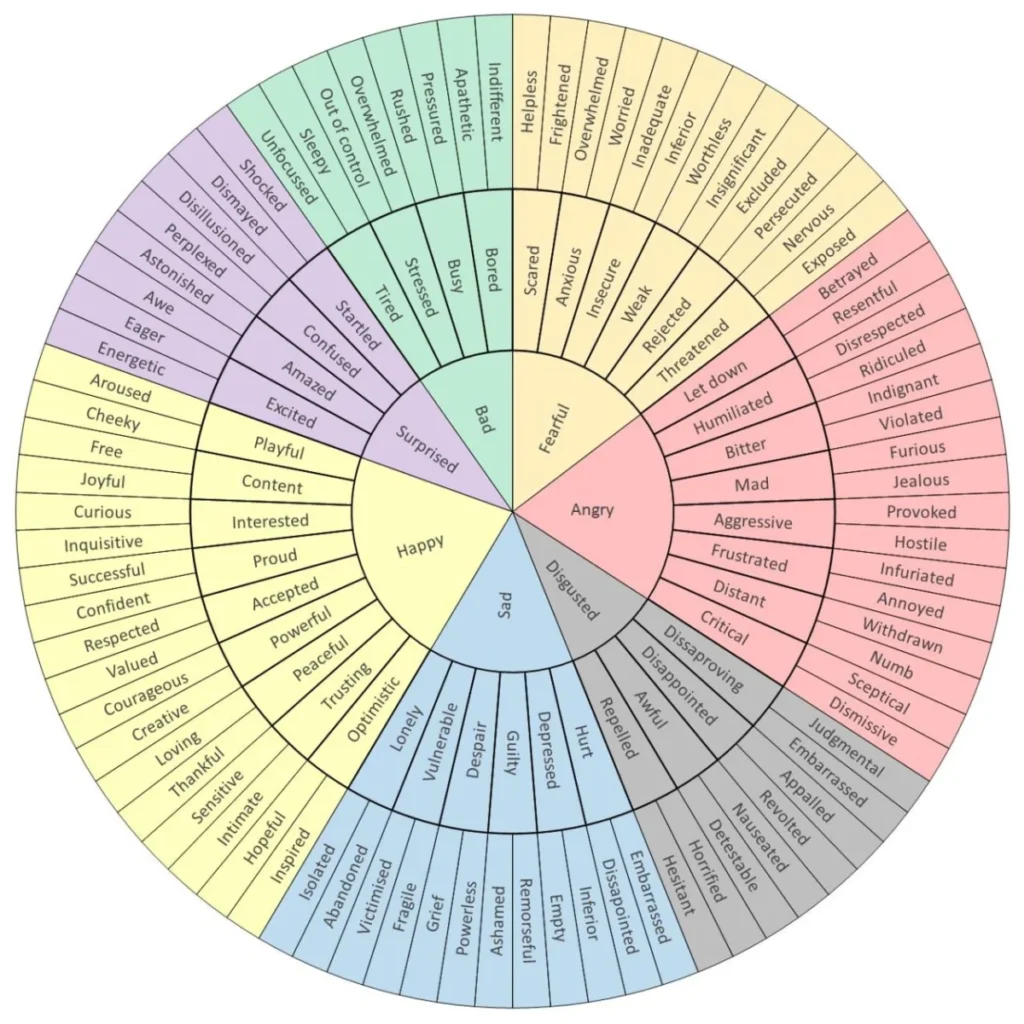
Posted inWeb Development
Beyond the Monolithic Agent: The Enterprise Shift Towards Scalable AI Teams
The current landscape of artificial intelligence interaction is largely defined by singular, conversational partners like ChatGPT or Claude, where users pose questions to a single agent that reasons, utilizes tools,…