
The Catalyst: A Developer’s Turning Point
The urgency of this architectural pivot was starkly illustrated by a critical incident experienced by a seasoned developer in October of an unspecified recent year, likely 2025 given the article’s 2026 perspective. While preparing to demo a project management tool in Lisbon, a meticulously crafted application—featuring a React front end, Node.js back end, PostgreSQL database, Redis cache, and a GraphQL API—rendered a blank screen and timeout error due to unreliable hotel Wi-Fi. Even with a shaky cellular connection, every interaction involved a frustrating two-second delay, forcing round-trips to a server thousands of miles away. This firsthand experience of a well-engineered application failing in a common real-world scenario became the immediate catalyst for a serious exploration of local-first architecture, not as an academic curiosity, but as an essential engineering requirement.
This incident underscored a fundamental vulnerability in traditional client-server models: their inherent reliance on continuous, high-speed network connectivity. For applications designed for productivity and collaboration, such dependencies can severely hamper user experience and operational efficiency, especially in regions with inconsistent internet access or during travel.
Understanding Local-First Architecture: A Paradigm Shift
Local-first architecture represents a profound departure from conventional web development paradigms. Crucially, it is often misunderstood and conflated with related but distinct concepts such as offline-first, Progressive Web Apps (PWAs), or simple cache-first strategies. While offline-first applications handle network loss gracefully, they still consider the server as the ultimate source of truth, with server-side data ultimately overriding local changes upon reconnection. Similarly, cache-first approaches, often implemented via service workers, are performance optimizations that deliver stale data faster but do not alter data ownership. PWAs, a delivery mechanism, offer installability and push notifications but do not define a data architecture.
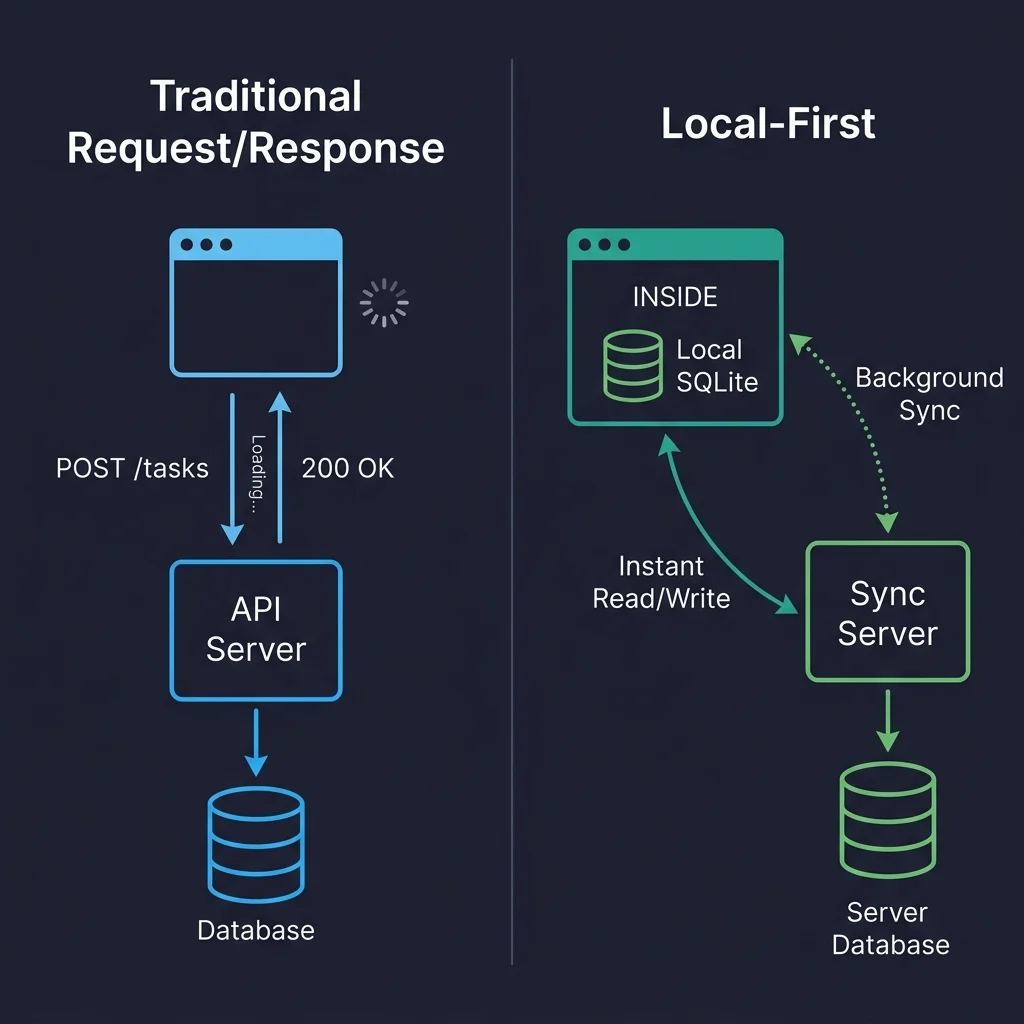
In contrast, local-first is fundamentally a data architecture. It posits that the user’s device maintains the primary, authoritative copy of their data. The application directly reads from and writes to a local database, providing instantaneous responses. Synchronization with servers or other devices occurs asynchronously in the background. The server, when present, functions as a peer in a distributed system, handling authentication, backups, and access control, but it is not the gatekeeper that dictates data availability or validity. This core principle—that "the client is not a thin view requesting permission to show data, but a node in a distributed system with its own database"—reshapes the entire application stack, from data fetching to state management and routing.
This concept can be likened to the evolution of version control systems from SVN to Git. SVN, a centralized model, halted operations if the server was down. Git, on the other hand, provides every developer with a full local clone, allowing them to commit, branch, and merge independently, pushing and pulling changes only when ready. Local-first web development applies this "Git-like" model to application data, where each client device holds a full or partial replica, writes occur locally, and synchronization is a background push/pull operation with defined conflict resolution strategies.
Strategic Application: When Local-First Excels and Falls Short
While the benefits of local-first architecture are compelling, it is not a universal solution. Its effective implementation requires careful consideration of the application’s specific requirements and data characteristics.
Ideal Use Cases:
Local-first architecture shines in applications where user-generated data is central and benefits from instant interaction, collaboration, and resilience to network outages. These include:
- Note-taking and Document Editing: Enabling seamless, real-time collaboration and offline productivity.
- Collaborative Design Tools: Allowing multiple users to work on designs simultaneously with immediate feedback.
- Project Management Systems: Facilitating task creation, updates, and organization even without network connectivity.
- Field Applications: Essential for industries where connectivity is unreliable (e.g., healthcare, logistics, construction).
- Privacy-Centric Applications: Where user data privacy is a key selling point, as data remains primarily on the device.
Situations to Avoid:
Conversely, local-first is a poor fit for applications characterized by:
- Server-Generated Data: Analytics dashboards, social media feeds, or search results, where the server is the data producer, and clients are primarily consumers.
- Strong Transactional Consistency: Banking, payment processing, or inventory management, where ACID guarantees are critical to prevent inconsistencies like double-spending or overselling. Eventual consistency in such contexts can lead to significant financial or operational risks.
- Simple CRUD Apps: For internal admin panels or basic data entry tools used by a small team with stable internet, the added complexity of a sync engine is often over-engineering.
- Massive Datasets: If the volume of data exceeds the practical storage capacity of client devices, full local replication becomes impractical.
A practical approach, often recommended by experienced developers, is to adopt local-first principles for specific features within a larger, otherwise traditional application. For example, implementing offline drafts in a blog editor or real-time collaborative notes within a standard REST-based project management tool can yield significant user experience benefits without requiring a full architectural overhaul. This incremental adoption allows teams to gain experience and validate the approach where it delivers the most value.

The Technological Foundation: Data Storage on the Client
The evolution of client-side data storage has been pivotal in making local-first a viable option. Early solutions like localStorage are fundamentally inadequate for complex applications, limited by synchronous access, small storage capacity (5-10 MB), and string-only data types. IndexedDB, while ubiquitous, asynchronous, and capable of handling hundreds of megabytes, is notorious for its cumbersome and developer-unfriendly API.
The breakthrough in 2026 lies in the robust implementation of SQLite running directly in the browser via WebAssembly (WASM). This is not merely a novelty; it provides a real relational database environment on the client, complete with full SQL query capabilities, transactions, and indexing. The Origin Private File System (OPFS), a newer browser API, is critical here, offering web applications a sandboxed, high-performance file system with synchronous access within Web Workers, which SQLite heavily leverages. This contrasts with earlier attempts to run SQLite in memory and manually persist to IndexedDB, which proved slower and less stable.
Libraries like wa-sqlite (WebAssembly SQLite) have emerged as reliable choices for integrating SQLite into browser environments. However, developers must navigate cross-browser inconsistencies; for instance, Safari’s OPFS implementation has presented subtle bugs, sometimes requiring a fallback to IndexedDB for persistence, albeit with a performance penalty. The emergence of PGlite, which compiles PostgreSQL to WASM, hints at an even more unified future, potentially allowing the same SQL dialect and logic to run on both client and server, further blurring the lines between client and server data layers.
The Synchronization Challenge: Replicating Data Across Devices
While local data storage is a mature problem, reliably syncing data across multiple devices and users remains the most complex aspect of local-first development. This is where the core of distributed systems engineering comes into play, requiring mechanisms to reconcile changes made independently across different replicas.
Conflict-Free Replicated Data Types (CRDTs): These are specialized data structures mathematically designed to ensure that concurrent edits can always be merged without conflicts. Yjs is a leading JavaScript implementation, particularly effective for real-time collaborative text editing, enabling multiple users to type simultaneously and see changes appear in a sensible, convergent order. Automerge, another significant CRDT library, offers a document-oriented model backed by Rust. Newer libraries like Loro are also emerging, promising enhanced performance.
Database Replication Engines: For most applications that do not require character-level real-time text collaboration, database replication is often a more practical approach. This involves replicating rows between a server database (e.g., PostgreSQL) and a client database (e.g., SQLite), with a dedicated sync engine managing the process.
- PowerSync: Provides one-way replication from PostgreSQL to client SQLite, with a defined write-back path for mutations. It offers a stable, production-ready solution, making it suitable for adding offline capabilities to existing PostgreSQL backends.
- ElectricSQL: Aims for a more ambitious active-active synchronization between PostgreSQL and SQLite, using "shapes" to define data replication. While offering an excellent developer experience in prototypes, it is still maturing for full-scale production deployments.
- Triplit: Represents a full-stack database approach with integrated sync, abstracting the distinction between client and server databases.
- Event Sourcing: Some solutions, like LiveStore, employ event sourcing, syncing a log of mutations rather than just the current state. While intellectually appealing and useful for audit trails, reconstructing state from an event log can add complexity that many applications do not require.
Navigating Conflicts: Strategies for Data Consistency
Conflict resolution, often perceived as a daunting challenge, is a manageable problem that necessitates a deep understanding of the application’s specific data model. A common and effective strategy is last-write-wins (LWW) at the field level, not the record level. If two users modify different fields of the same record concurrently, both changes are preserved. A conflict only arises when the same field is modified, in which case the change with the later timestamp is chosen. A deterministic tie-breaker (e.g., client ID) is often used for identical timestamps. This approach handles approximately 95% of conflicts without user intervention.
More complex are semantic conflicts, where data merges cleanly at a structural level, but the resulting state is logically inconsistent or nonsensical (e.g., two users booking the same meeting slot). Resolving these requires application-level validation, typically performed on the server during the write-back phase. The recommended strategy is to accept the conflicting write but flag the violation, rather than outright rejecting it. Rejecting a write can lead to divergence between the client’s local state and the server’s, creating "ghost records" that are difficult to resolve. By accepting and flagging, the server stores the violation and syncs it back to the client, which then displays a non-blocking notification to the user, prompting them to resolve the conflict (e.g., reschedule a meeting). This approach prioritizes data availability and user experience, acknowledging that for certain domains, a brief window of inconsistency is preferable to data loss or unresolvable state divergence. However, it underscores why local-first is generally unsuitable for systems demanding strong transactional consistency.
For CRDTs, character-level text editing conflicts are resolved elegantly. However, CRDT merging of structured data (e.g., lists, nested objects) can sometimes yield results that are technically correct but practically confusing, potentially requiring post-merge deduplication or specific list merge semantics. User-facing merge conflicts, akin to Git, are generally avoided in typical application data, as users prioritize automated resolution over manual intervention.
Building Robust Local-First Applications

Implementing a local-first architecture involves a distinct set of considerations for the overall application stack, authentication, and schema management.
Architectural Stack: A typical modern stack for a collaborative local-first application might involve React for the front end, PowerSync for robust data synchronization, SQLite via wa-sqlite on the client (persisted to OPFS with an IndexedDB fallback for broader browser compatibility, especially Safari), and a backend platform like Supabase (offering PostgreSQL, authentication, and row-level security). This combination allows for reactive UI updates driven by local database changes, significantly reducing the complexity of data fetching, loading states, and cache invalidation compared to traditional REST/GraphQL architectures.
Authentication and Authorization: Authentication generally follows traditional patterns, using JWT tokens or OAuth flows. The token authenticates the sync connection, allowing offline access to previously synced data. Authorization, however, is critically enforced at the sync layer. Solutions like PowerSync’s "sync rules" or ElectricSQL’s "shapes" define which rows are replicated to specific clients, preventing unauthorized data from ever reaching a user’s device. Client-side code cannot be trusted to hide sensitive data. Furthermore, server-side validation ensures that any client-initiated writes adhere to authorization rules before being applied to the primary database. The inherent data locality also makes end-to-end encryption (E2EE) a natural fit, allowing data to be encrypted on the client before synchronization, with the server acting as a relay for unreadable encrypted blobs.
Schema Migrations: Client-side schema migrations present a unique challenge compared to server-side migrations. Each user’s local database may be at a different schema version, depending on when they last updated or opened the application. A robust migration runner is essential, checking the client’s current schema version at app startup and applying additive migrations incrementally. Developers must design migrations carefully, adding new columns with defaults or new tables, and avoiding renaming or dropping columns that older client versions might still be writing to. Failure to do so can lead to silent sync failures and data inconsistencies for users on older app versions.
Performance and Operational Considerations
The performance benefits of local-first are undeniable. Reads and writes against a local SQLite database are virtually instantaneous, typically completing in milliseconds, eliminating network latency and the need for loading spinners or optimistic update logic.
However, these benefits come with operational considerations:
- Initial Sync Cost: The initial bootstrap of a local replica can involve downloading megabytes of data, leading to a noticeable "Setting up your workspace" screen for new users or devices. Strategies like partial sync (only replicating active projects) and aggressive data pruning help mitigate this.
- Bundle Size: SQLite compiled to WASM adds a significant amount (around 400KB gzipped) to the JavaScript bundle. Lazy-loading the database module can prevent it from blocking initial render.
- Memory Footprint: SQLite WASM operates in memory, and large datasets on mobile browsers with strict memory limits can lead to tab crashes. Managing dataset size through partial sync and data pruning is crucial.
- Testing Complexity: Testing local-first applications is inherently more complex due to their distributed nature. While unit tests for merge logic and integration tests for convergence are feasible, reproducing timing-specific conflict resolution bugs remains challenging. Detailed logging of sync events and property-based testing for CRDT logic are valuable strategies.
The Future Landscape and Emerging Challenges
The local-first ecosystem is evolving rapidly. Innovations like PGlite (PostgreSQL in the browser) hint at a future where the client/server data layer distinction might dissolve, allowing developers to write SQL that runs universally. The convergence of local-first with on-device AI models offers compelling privacy advantages, enabling "your data never leaves your device" as a powerful product differentiator.
Despite this promising outlook, significant challenges remain. Fragmentation is a primary concern; the lack of a standardized sync protocol means each sync engine employs its proprietary method. This absence of interoperability creates vendor lock-in and complicates migration between platforms. The complexity budget is another critical factor. While local-first offers substantial benefits for specific applications and experienced teams, it introduces considerable architectural complexity (sync engines, conflict resolution, client-side migrations, partial replication, sync-layer authorization). For simpler CRUD applications, this added overhead can become a "trap," leading to over-engineering and increased maintenance burden.
As one developer aptly put it, "The best architecture is the one your team can debug at 2 AM." This emphasizes the importance of understanding the failure modes and operational nuances of local-first systems before full adoption. Starting with a single feature that demonstrably benefits from instant local reads and offline writes, then gradually expanding, is often the most prudent path. The journey into local-first architecture is not without its complexities, but for developers willing to navigate them, it promises a future of faster, more reliable, and more user-centric web applications.



{kind=link}